Building with Supabase
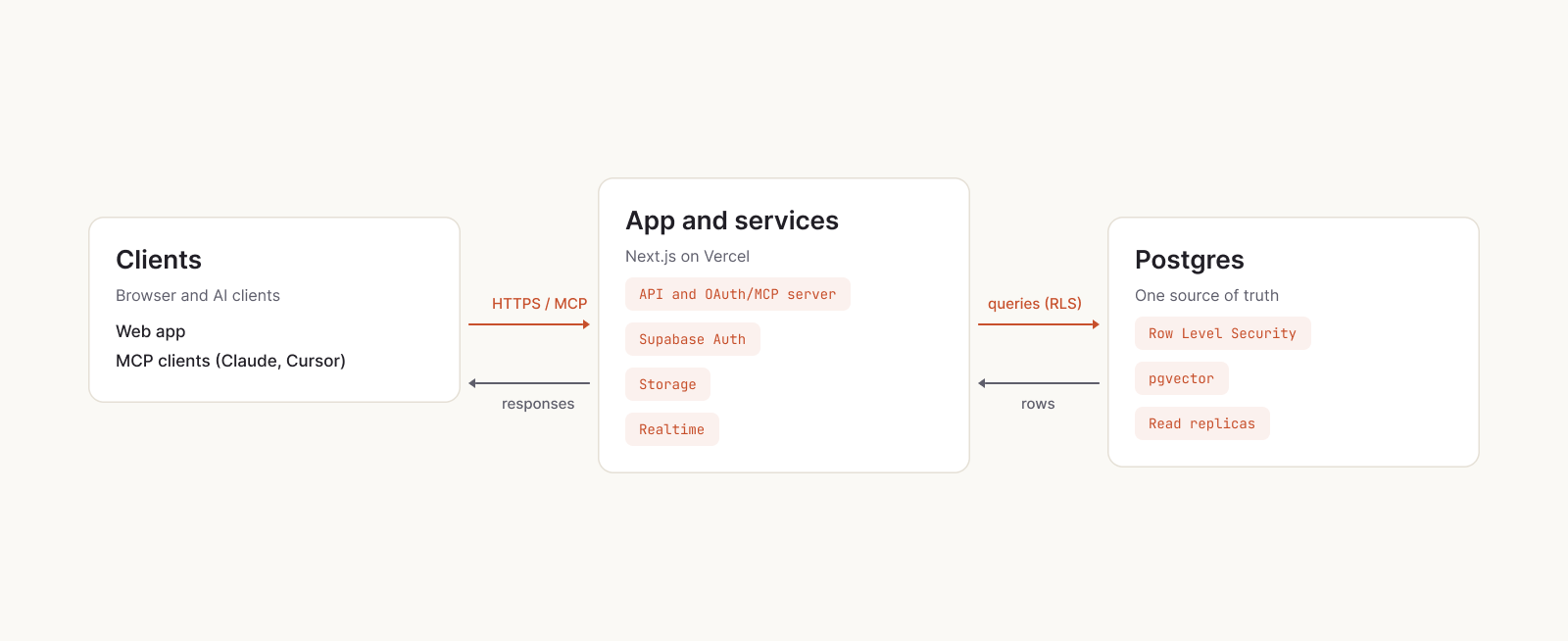
How we run a multi-tenant AI agent platform on Supabase: row level security for tenant isolation, OAuth and passkeys for humans and machines, pgvector for agent RAG, read replicas for global reads, and preview branches for every pull request.
How we've used Supabase as a platform to build and scale Stunt Double
Authentication: passwordless, Google, and passkeys without building a login system
We never wanted to store passwords, and with Supabase Auth we don't have to. Sign-in is passwordless out of the box: magic links by email, Google, and now passkeys, which are the nicest of the three. Once a user registers a passkey, signing in is a single biometric prompt with nothing to phish, and because authentication and authorisation share one identity, there is no seam to maintain between who someone is and what they are allowed to see.
An OAuth server for MCP clients: safe machine access on the same identity
Stunt Double speaks the Model Context Protocol, so people can drive their workspace from AI clients like Claude or Cursor: run a checklist, list actors, open a Linear issue from the findings. For that to be safe, the client has to act on a user's behalf with permission and without holding secrets it shouldn't. Because identity already lives in Postgres, we built a standards-based OAuth 2.1 server straight on top of it rather than bolting on separate infrastructure. Machine access lands inside the same access rules as a browser session, so every request, whether it comes from a person or a model, resolves to the same identity and the same permissions.
Row Level Security: multi-tenant isolation the database enforces
Stunt Double is multi-tenant. Every customer is a workspace, and nearly every row belongs to one. The property that matters most is that one workspace can never see another's data, and we enforce it in the database with Row Level Security rather than trusting every query in the app to remember its filter. If a query forgets, Postgres still refuses to return rows the user shouldn't see. The policy is the backstop, and it runs on every query. The payoff for development speed is real: isolation is solved once, at the foundation, so building a new tenant-scoped feature never reopens the question of whether it is safe.
Preview branches and migrations: a real database for every pull request
Open a pull request and Supabase spins up an ephemeral Postgres branch seeded from our migration history. Merge or close it, and the branch is torn down. For a product where most changes touch the schema, this is the feature that changed our pace the most. Migration ordering and collisions surface in review instead of production, new policies can be exercised against seed data before they reach a real customer, and the branch pairs with our Vercel preview so a reviewer clicks one link and gets the whole stack. Schema work went from the scariest part of the codebase to the most routine.
pgvector and embeddings: agent retrieval without a separate vector store
Actors get sharper when you give them knowledge, which means retrieval-augmented generation. The usual cost of entry is running a separate vector database with its own scaling, backups, and permission model to keep in step. pgvector keeps embeddings and similarity search inside the same Postgres, so retrieval runs through the same engine and the same access rules as everything else. There is no second system to operate or secure, and an actor can only ever reach knowledge from its own workspace, by construction.
Realtime: live UI sync and streaming without your own socket layer
Actor runs are long-lived, and the interface needs to feel alive while they happen. Supabase Realtime pushes changes from the database to the client, so progress streams in as a run executes and any update, a finding landing or a run completing, appears across open sessions immediately. We get a live, in-sync UI and streaming agent output without standing up and maintaining our own websocket service.
Storage buckets: images and files behind the same access rules
Checklist runs capture screenshots, and knowledge bases accept uploaded documents, so the platform needs somewhere to put images and files. Supabase Storage handles it with buckets, and access is governed by the same kind of policies as the rest of the data, so a file is only reachable by the workspace it belongs to. That is object storage with workspace isolation built in, rather than a separate store plus a CDN plus its own permission layer to keep in sync.
Read replicas: global reads with the same guarantees
As usage spread across regions, read latency started to matter. Read replicas fixed it as a configuration change rather than an engineering project: reads route to the nearest region, and writes stay on the primary. Because the rules live in the database, every guarantee travels with the data, so there was never a "does isolation still hold once we copy data around" conversation. Faster reads everywhere, and nothing about the security model to reconsider.
Generated TypeScript types: a schema the code can't drift from
Our codebase is TypeScript, and Supabase generates types straight from the database schema. That makes the schema the single source of truth: a change to a table shows up as a change to the types, and any mismatch between the database and the code is caught by the compiler instead of at runtime. It removes a whole layer of hand-written boilerplate and keeps the app and the database honest with each other as both evolve.
One foundation
The thread through all of it is that these are not nine separate systems. Authentication, machine access, isolation, retrieval, realtime, storage, and global reads all resolve to the same Postgres, governed by the same rules. The platform gets more capable without getting more complex, and that is what lets us keep shipping. Supabase does the heavy lifting underneath, which is exactly the point.
Keep reading
- 4 min
Building a Self-Healing Product Feedback Loop
Turn error signals and feedback into almost instant product improvements with triage and cloud coding agents.
- 3 min
What Is MCP and Why It Matters for Product Teams
The Model Context Protocol lets AI assistants call tools in external services. For product teams, that means testing, feedback, and issue tracking without leaving your editor.
- 1 min
For Humans & Their Machines
User-centred design in a world with AI agents.